Everyone is talking about Large Language Models (LLMs). Since ChatGPT became mainstream in December 2022, the world has never been the same. Industries across the board—finance, manufacturing, and commerce—are racing toward the implementation of AI.
Recently, LLMs have been introduced in self-driving cars, in the form of Vehicle Language Models (VLMs). These models allow humans to interact with autonomous vehicles by answering questions about what the car sees through its cameras. This capability, known as Visual Question Answering (VQA), lets the vehicle understand and explain its environment to the user. Today, we’ll look at Lingo QA, a system developed by Wayve in 2023 to improve VQA in autonomous cars.
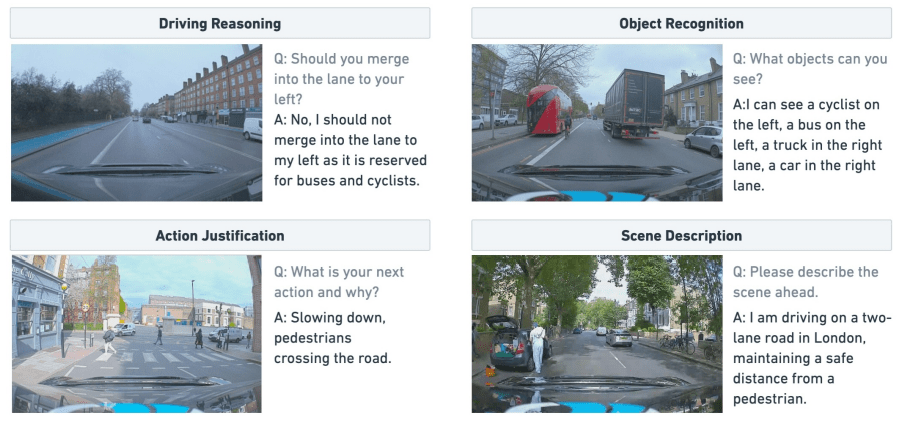
What is the Paper about?
Lingo QA addresses the explainability problem in autonomous driving. The paper introduces a VQA system that enables human to chat with their autonomous car via text. This technology aims to bridge the gap between machine decision-making processes and human understanding. LingoQA can interpret various driving situations, such as surrounding object recognition and the car’s action justification.
Contributions of the Paper
The paper contributions include:
- Dataset: Consists of thousands of scenarios that can be used to benchmark Video Question Answering (VQA) system.
- LingoJudge: An evaluation metric which correlates well with human judgements, making it reliable for VQA assessment.
- The LingoQA Baseline Model: A vision language architecture containing CLIP, Q-former (Querying Transformer), and LLM.
The Lingo QA Baseline Model Architecture
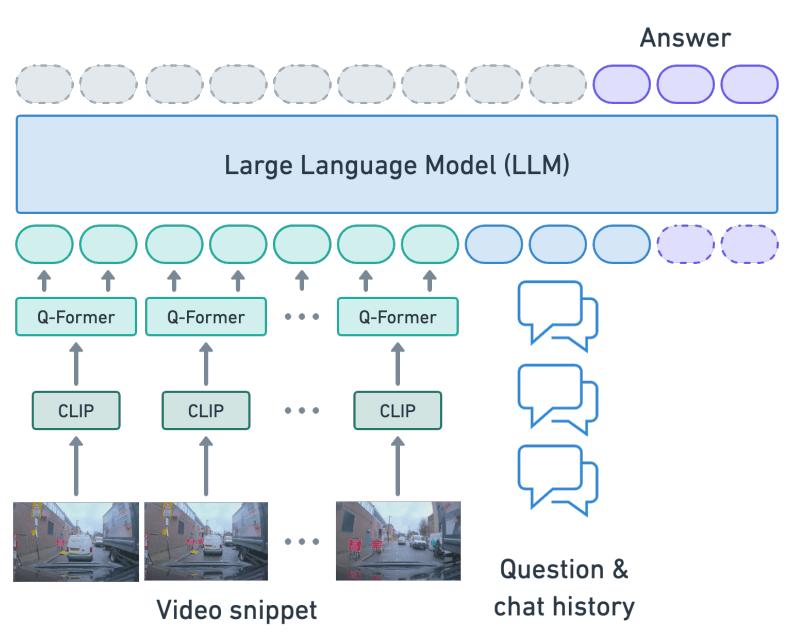
The model works by first inputting the video frame into CLIP, which encodes the video frame (image) into feature. The encoded feature is then received by Q-Former, that converts the encoded vision feature into language space. Finally, the output from Q-Former is passed to the LLM, which utilizes the information to respond to user prompts.
Results
The results demonstrate the effectiveness of the Lingo QA baseline model. When tested on the LingoQA benchmark, the model showed a strong ability to answer questions related to driving reasoning, object recognition, action justification, and scene description. The novel evaluation metric, Lingo-Judge, achieved a Spearman correlation coefficient of 0.95 with human evaluations, indicating high reliability in assessing the model’s performance.
Conclusion
In summary, the Lingo QA makes significant progress toward making autonomous driving systems more explainable. The dataset, LingoJudge evaluation metric, and the Lingo QA Baseline model provide a strong foundation for future advancements in explainable AI for self-driving car.
***
Reference:
- Marcu, A. M., Chen, L., Hünermann, J., Karnsund, A., Hanotte, B., Chidananda, P., … & Sinavski, O. (2023). Lingoqa: Video question answering for autonomous driving. arXiv preprint arXiv:2312.14115.

Leave a comment